
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- GIT
- claude code
- 오블완
- elasticsearch
- Intellij
- RDS
- 아키텍트
- 구조체
- GoF
- Kubernetes
- goland
- 감상문
- 디자인패턴
- esbuild
- 캡슐화
- ai agent
- Infra
- AWS
- OpenClaw
- 티스토리챌린지
- typescript
- LLM
- golang
- EKS
- logging
- Harness Engineering
- MSA
- DB
- go
- AI
- Today
- Total
Fall in IT.
Elasticsearch 로그 저장소 문제 해결 사례 본문
최근 연차를 보내던 중 QA 팀으로부터 서비스의 로그인 오류 문의를 받았다.
문제의 원인을 조사하고 해결한 과정을 기록한다.
문제 상황
QA 팀에서는 서비스 로그인이 되지 않는다고 보고했다.
로그를 확인해 보니 API 타임아웃이 발생하고 있었다.
원인 분석
- 로그 기록 방식
API 에러가 발생한 서비스는 로그를 로그 라이브러리를 통해 Elasticsearch에 기록하고 있었는데 동기적으로 기록하고 있었다.
이 방식은 Elasticsearch에 문제가 생기면 API 요청이 지연되거나 실패할 수 있는 구조적 문제를 내포하고 있었다. - Elasticsearch 상태 점검
- Elasticsearch는 실행 중이었으나 에러 로그가 기록되고 있었다.
- 스토리지 상태를 확인한 결과, /usr/share/elasticsearch/data 디렉터리의 저장 공간이 100% 사용 중이었다.
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme1n1 974M 958M 0 100% /usr/share/elasticsearch/data문제 해결 과정
해결 방법 선택
먼저, Elasticsearch를 빠른시간안에 정상화 시켜야했기 때문에 /usr/share/elasticsearch/data 디렉터리를 정리하여 저장 공간을 확보하기로 결정했다.
두 가지 접근 방식을 고려했는데,
- Elasticsearch API를 활용하여 불필요한 인덱스 삭제
- API를 통해 특정 인덱스를 삭제하는 방법
- Elasticsearch 데이터 디렉터리 내 로그 파일 직접 삭제
- 서버에 접속해 오래된 데이터를 삭제하는 방식
Elasticsearch API를 잘 알지 못해 2번을 선택했다.
실제 조치
1) Kubernetes의 Elasticsearch Pod에 접속
$ kubectl exec -it <elasticsearch-pod-name> -n <namespace> -- /bin/bash2) 데이터 삭제
$ rm -rf /usr/share/elasticsearch/data/*
3) Elasticsearch 파드 재시작
$ kubectl delete pod <elasticsearch-pod-name> -n <namespace>재시작 후 Elasticsearch는 정상적으로 작동했다.
개선 방안
이번 문제를 통해 시스템의 개선이 필요함을 느꼈다.
- 비동기 로그 기록 방식으로 전환
- 동기 방식은 로그 기록 실패 시 서비스 전체에 영향을 줄 수 있다.
- 비동기로 전환해 이러한 문제를 방지해야 한다.
- Elasticsearch 메모리 늘리기
- PVC의 용량이 매우 작게 설정되어 있기 때문에 PVC 용량을 더 큰 용량으로 설정할 필요가 있다.
- Elasticsearch 인덱스 관리 자동화
- 불필요한 인덱스를 자동으로 삭제하거나 주기적으로 데이터를 백업 및 정리하는 스크립트를 도입해야 한다.
PVC의 용량을 10Gi로 늘리고 ILM 설정하기 (Index Lifecycle Management)
1) PVC의 용량을 10Gi로 늘리기
기존 PVC와 PV 용량을 1Gi에서 10Gi로 늘리는 방법은 쿠버네티스 환경에서 스토리지 클래스가 확장 가능한 경우에만 가능하다. 그렇지않은 경우는 PVC와 PV를 재생성해야한다.
1. 스토리지 클래스 확인
PVC 확장이 가능한지 확인하려면 먼저 사용중인 스토리지 클래스 (StorageClass)를 확인해야한다.
# 모든 스토리지 클래스 조회
$ kubectl get storageclass
# 확장하고자하는 스토리지 클래스 세부 정보 확인
# AllowVolumeExpansion: True 가 표시되어있어야 확장이 가능
$ kubectl describe storageclass <storageclass-name>
스토리지 클래스 조회 결과
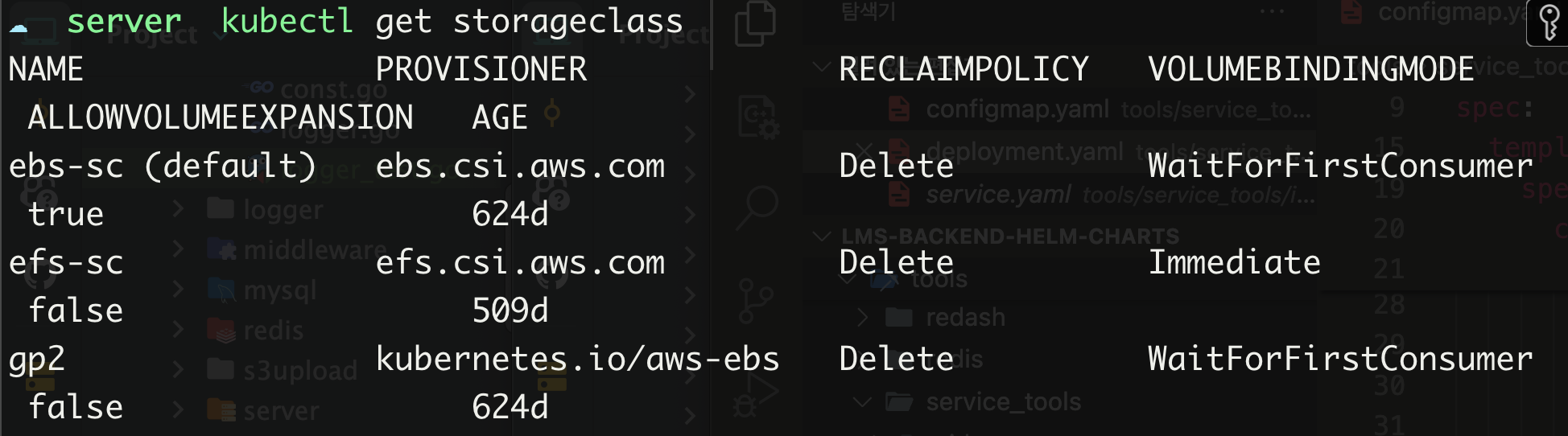
만약, AllowVolumeExpansion 속성이 <unset>으로 되어있는 경우 먼저 활성화를 시켜줘야 한다.
AllowVolumeExpansion 활성화
1) 스토리지 클래스에서 확장을 활성화하는 명령어를 실행한다.
$ kubectl patch storageclass <storageclass-name> -p '{"allowVolumeExpansion": true}'
2) 수정 확인
$ kubectl describe storageclass <storageclass-name>
3) 활성화 확인 결과

2. PVC 확장
AllowVolumeExpansion이 활성화되었으면 기존 PVC의 크기를 확장할 수 있습니다.
# PVC 크기 확장 명령어 (10Gi로 확장한다고 가정한다)
$ kubectl patch pvc <pvc-name> -n <namespace> --type='json' -p='[{"op": "replace", "path": "/spec/resources/requests/storage", "value": "10Gi"}]'
# 확장된 크기 확인
$ kubectl get pvc <pvc-name> -n <namespace>
확장된 결과

2) ILM 설정하기 (Index Lifecycle Management)
Elasticsearch의 ILM은 인덱스의 수명주기를 자동으로 관리하여 저장소를 효율적으로 사용하도록 돕는 기능이다.
1. ILM 정책 생성 명령
# 예를 들어, 데이터를 10일 동안 유지한 뒤 삭제하는 정책을 생성하려면 아래 명령을 사용한다.
# hot 단계: 인덱스가 생성된 뒤 10일 동안 데이터를 저장하며, 최대 크기 10GB까지 유지한다.
# delete 단계: 10일이 지난 인덱스를 삭제
$ curl -X PUT "http://<elasticsearch-host>:9200/_ilm/policy/delete-after-10d" -H 'Content-Type: application/json' -d'
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_size": "10gb",
"max_age": "10d"
}
}
},
"delete": {
"min_age": "10d",
"actions": {
"delete": {}
}
}
}
}
}'
2. 인덱스 템플릿에 ILM 정책 연결
ILM 정책을 새로운 인덱스에 자동으로 적용하려면 인덱스 템플릿을 생성하거나 수정해야한다.
인덱스 템플릿 생성
$ curl -X PUT "http://<elasticsearch-host>:9200/_index_template/logs-template" -H 'Content-Type: application/json' -d'
{
"index_patterns": ["logs-*"],
"template": {
"settings": {
"index.lifecycle.name": "delete-after-10d", // ILM 정책 이름
"index.lifecycle.rollover_alias": "logs-alias" // Rollover를 위한 alias
}
}
}'
3. Rollover Alias 설정
Rollover는 특정 인덱스가 지정된 조건(크기, 문서 수, 기간)을 초과하면 새로운 인덱스를 생성하는 기능이다. 이를 통해 대형 인덱스를 작은 단위로 분리하여 성능 및 관리 효율성을 높일 수 있다.
- 예를들어, api-log-000001라는 인덱스가 10GB를 초과하거나 10일 이상 된 경우 api-log-000002라는 새로운 인덱스를 생성
- Alias 사용은 새롭게 생성된 인덱스에 Alias를 연결하여 애플리케이션에서 동일한 이름으로 데이터를 계속 작성이 가능하도록 한다.
ILM 정책이 작동하려면 인덱스에 Rollover Alias가 설정되어 있어야 한다.
초기 인덱스 생성 및 Alias 설정
# logs-000001: 첫 번째 물리적 인덱스 이름
# logs-alias: Rollover를 위한 alias 이름
$ curl -X PUT "http://<elasticsearch-host>:9200/logs-000001" -H 'Content-Type: application/json' -d'
{
"aliases": {
"logs-alias": {
"is_write_index": true
}
}
}'
4. 기존 인덱스에 ILM 정책 적용
기존 인덱스에도 ILM 정책을 적용할 수 있다. 하지만 Rollover Alias가 없는 기존 인덱스는 Rollover를 사용할 수 없으므로 정책을 간단히 수정해야한다.
$ curl -X PUT "http://<elasticsearch-host>:9200/<index-name>/_settings" -H 'Content-Type: application/json' -d'
{
"index.lifecycle.name": "delete-after-10d"
}'
5. ILM 상태 및 진행상황 확인
# 모든 ILM 정책의 상태 확인
$ curl -X GET "http://<elasticsearch-host>:9200/_ilm/policy?pretty"
# 특정 인덱스의 ILM 상태 확인
$ curl -X GET "http://<elasticsearch-host>:9200/<index-name>/_ilm/explain?pretty"
6. 자동 삭제 확인
정상적으로 설정되었다면 ILM 정책에 따라 10일이 지난 인덱스는 삭제됩니다. ILM 정책의 작업 기록은 Elasticsearch의 로그에서 확인할 수 있다.
결론
이번 사례는 단순한 디스크 용량 문제처럼 보였지만, 로그 기록 방식과 모니터링 체계의 중요성을 다시 한번 확인하는 계기가 되었다.
또한, PVC 용량 확장과 ILM 설정은 Elasticsearch 운영에 있어 중요한 부분이다.
- PVC 확장은 서비스 중단 없이 스토리지 용량 문제를 해결할 수 있다.
- ILM 설정은 저장 공간을 효율적으로 사용하고, 시스템 성능을 유지하는 데 필수적이다.
'시스템구축' 카테고리의 다른 글
| DDNS란 무엇인가? (0) | 2024.11.22 |
|---|---|
| 로그 데이터를 수집하는 방법에 대해서 (0) | 2024.11.17 |
| 간단한 알림 시스템 설계 (0) | 2024.01.13 |
| System Design을 위한 기본 기능 정리 (2) | 2023.12.31 |
| Kubernetes를 사용하는데 Helm이 필요한 이유와 간단 사용방법 (0) | 2023.02.06 |


