
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- typescript
- 캡슐화
- MSA
- Infra
- 티스토리챌린지
- 디자인패턴
- sqs fifo queue
- replication lag
- logging
- goland
- 구조체
- GIT
- Kubernetes
- go-sql-driver
- context7
- GoF
- 오블완
- AI
- 관측 가능성
- database/sql
- RDS
- 통합 로깅 시스템
- esbuild
- Intellij
- golang
- blank import
- javascript
- AWS
- go
- elasticsearch
- Today
- Total
Fall in IT.
System Design을 위한 기본 기능 정리 본문
대규모 System Design을 위한 몇 가지 기본 기능을 간단하게 정리해보자.
(대규모 시스템을 설계하기 위해서는 많은 기술들이 필요하지만 이 글에서는 로드밸런서, 메시지 큐, 캐시에 대한 개념을 간단히 정리해보겠습니다)
로드밸런서
로드밸런서는 부하 분산 집합에 속해 있는 웹 서버들에게 트래픽을 고르게 분산하는 역할을 한다.

사용자는 로드밸런서의 공개 IP 주소(public IP address)로 접속한다.
웹 서버는 클라이언트의 접속을 직접 처리하지 않는다. 또한, 서버 간의 통신은 사설 IP 주소(private IP address)를 이용한다.
이렇게 되면, 서버의 확장 및 축소가 쉬워지는데 부하 분산 집합에 웹 서버를 추가하거나 삭제함으로써 필요에 따라
서버의 규모를 확장하거나 축소할 수 있다.
또한, 하나의 서버에 장애가 생겼을때 장애가 없는 서버쪽으로 트래픽이 전달되어 서버 전체가 다운되는 일을 방지할 수 있다.

메시지 큐
메시지 큐는 메시지의 무손실을 보장하는 비동기 통신을 지원하는 컴포넌트이다.
핵심은 무손실과 비동기 통신에 있다.
메시지 큐는 기본적으로 발행자(Publisher or Producer)와 구독자(Subscriber or Consumer)가 존재한다.
메시지가 누적되는 큐에 발행자는 메시지를 전송하고 구독자는 큐에 쌓인 메시지를 가져가 처리하는 구조이다.
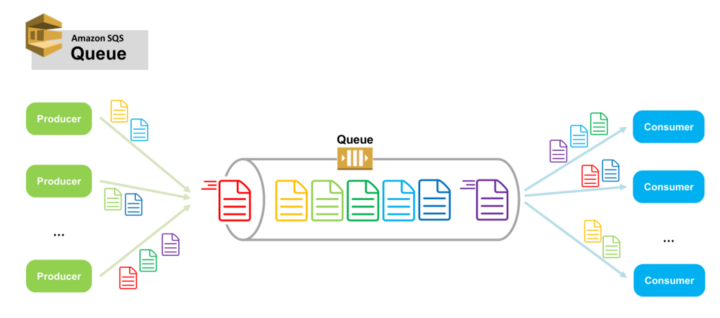
이 간단한 구조는 마이크로서비스에서 서비스 또는 서버 간의 결합을 느슨하게 만들어주고 안정적인 애플리케이션을 구성할 수 있도록 도와준다.
왜 메시지 큐는 안정적인 서비스를 할 수 있게 도와주는가?
발행자(A 서비스)는 구독자(B 서비스)가 죽었는지 살았는지 상관없이 메시지를 발행할 수 있고, 반대로 구독자 또한 발행자의 상태와는 상관없이 메시지를 수신할 수 있다. 만약, 구독자(B 서비스)가 오랜시간 죽었다가 살아났다고 하더라도 발행자는 메시지 큐에 메시지를 안전하게 전송해 두었기 때문에 구독자는 메시지 큐의 메시지를 가져다가 처리할 수 있다.
그 외에도, 특정 메시지가 필요한 다양한 서비스들이 존재한다면 단순히 구독을 설정하고 필요한 메시지를 받아서 처리하면 되기때문에 서비스 확장에도 큰 이점이 생기게 된다.
그렇다면, 비동기 통신은 어떤 점이 좋은걸까?
시간이 오래 걸리는 프로세스는 동기적인 처리보다 비동기적으로 처리하는게 안정적이다.
예를들어보자. 이미지 처리하는 프로세스가 동작해야한다고 할때 발행자는 이미지 프로세싱이 필요한 데이터를 큐에 발행하고 구독자는 큐에 들어온 데이터를 처리하는데 큐에 들어오는 메시지의 수가 많다면 구독자를 늘리고 적다면 구독자를 줄이면서 요청수에 따라 자유롭게 scaling 할 수 있다.
캐시
캐시는 연산 시간이 오래 걸리는 데이터 또는 자주 조회되는 데이터를 메모리 안에 저장해두고 빨리 응답할 수 있도록 하는 기술이다.
데이터를 메모리에 저장해두는게 핵심이다.
애플리케이션 성능은 데이터를 데이터베이스에서 조회하는데 크게 좌우되는데, 캐시를 사용하면 그런 문제들을 완화 할 수 있다.

캐시 전략은 굉장히 다양한데, 해당 글에서는 캐시 전략에 대해서는 언급하지 않겠습니다.
캐시 사용 시 고려해야할 사항
- 캐시는 언제 사용하지?
- 데이터 업데이트는 자주 일어나지 않고 조회는 빈번하게 일어나는 경우
- 캐시의 신선도는 어떻게 보장하지? (최신 데이터가 맞을까?)
- 컨텍스트에 따라 적당한 정책이 필요하다.
- 캐시의 만료 시점을 적절하게 정하는게 매우 중요하다.
- 데이터의 일관성을 위해 업데이트는 원본 데이터가 갱신될때 단일 트랜잭션으로 캐시 데이터도 갱신 되어야한다.
- 캐시 서버의 장애는 어떻게 대응할 것인가?
- 캐시 서버도 장애가 발생할 수 있기 때문에 다중화가 필요하다. (다중화 된다면, 캐시 서버의 동기화 정책도 필요하다)
- 캐시 서버도 장애가 발생할 수 있기 때문에 다중화가 필요하다. (다중화 된다면, 캐시 서버의 동기화 정책도 필요하다)
참고
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초로드밸런서
'시스템구축' 카테고리의 다른 글
| Elasticsearch 로그 저장소 문제 해결 사례 (2) | 2024.11.15 |
|---|---|
| 간단한 알림 시스템 설계 (0) | 2024.01.13 |
| Kubernetes를 사용하는데 Helm이 필요한 이유와 간단 사용방법 (0) | 2023.02.06 |
| AWS 인프라 구성 간단하게 맛보기(VPC, Subnet, IGW, NAT, SSH Tunneling) (0) | 2023.01.22 |
| Github 계정 엑세스 토큰 생성 방법 (0) | 2023.01.05 |



